시간 복잡도 (Time Complexity)
시간복잡도를 알아야하는 이유
알고리즘 공부나 코딩테스트를 위해 백준 등과 같은 문제를 풀다보면 꼭 마주하는 것이 있다.
바로 시간이다.
실력이 늘다보면 어떠한 방법으로던 문제는 해결하지만,
입력받는 값이 커지면 시간이 기하급수적으로 증가해 제한시간 안에 정답을 도출하지 못한다.
이럴 때 쓰이는게 시간복잡도이다. 시간복잡도를 통해 걸리는 시간을 대략적으로 계산해보면, 문제에 맞는 어떤 알고리즘을 사용해야 할지 판단할 수 있다.
백준 단계별 문제에서도 시간복잡도에 대한 파트가 따로 있다.
시간 복잡도(Time Complexity)
- Big-O(빅-오) ⇒ 최악의 경우 : 가장 오래 걸리는 시간
- Big-Ω(빅-오메가) ⇒ 최선의 경우 : 최소한 걸리는 시간
- Big-θ(빅-세타) ⇒ 평균의 경우 : 평균적으로 걸리는 시간
이해를 위한 예시 - 버블정렬
def bubbleSort(arr):
n = len(arr)
for i in range(n-1, -1, -1):
for j in range(0, i):
if arr[j] arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
arr의 길이가 10만 이하인 테스트 케이스를 넣는다고 하자.
그럼 각각 몇번 for문의 반복이 이루어졌는지 계산해보자.
Big-O(빅-오) ⇒ n=10만인 경우 : 10만 x 10만 =100억번 반복이 이루어진다.
Big-Ω(빅-오메가) ⇒ n=1인 경우 : 1x1번 =1번 연산을 수행한다.
이렇듯 테스트 케이스의 값이 작다면 크게 오래걸리지 않겠지만,
테스트케이스의 값이 커질수록 엄청난 차이를 가져올 수가 있다.
하지만 가장 중요한건 바로 최악의 경우인 Big-O(빅-오) 이다.
항상 우리는 주어진 시간 내에 해결하기 위해서는 최악의 테스트 케이스를 생각하고 코드를 짜야한다.
Big-O 표기법에 따른 복잡도 그래프
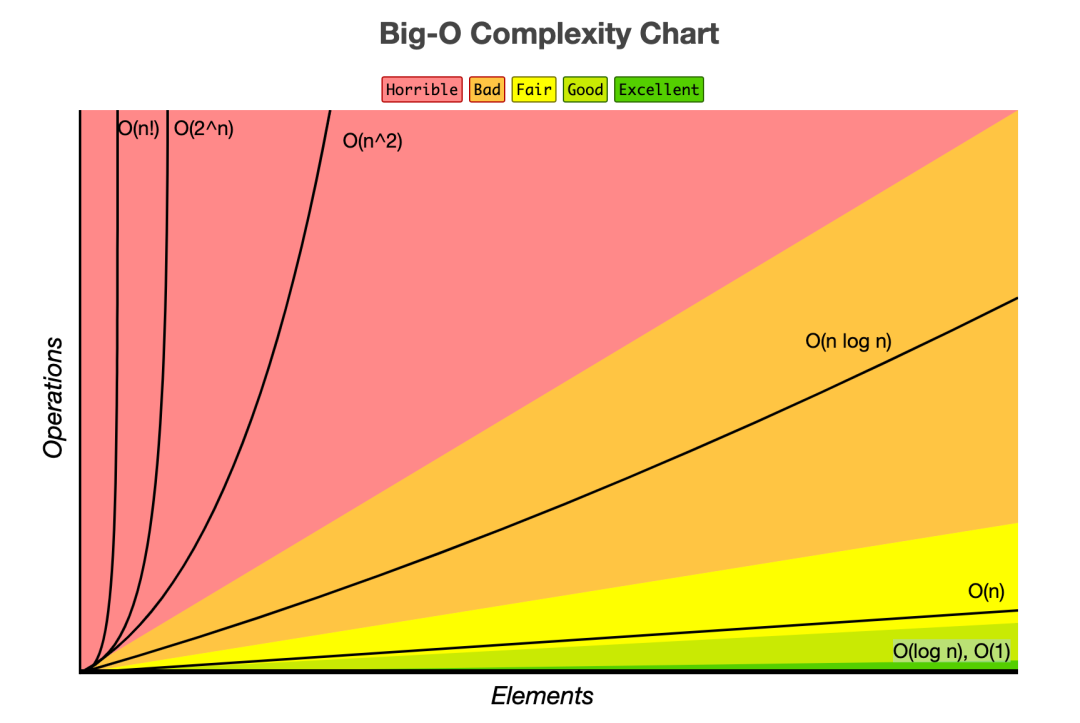
상수는 무시한다 !
다음 예시는 시간복잡도가 O(n) 인 코드이다.
n = int(input())
print('1부터 n까지 2배씩 곱해주어 출력하기')
for i in range(1, n+1):
i*=2
print(i, end=' ')
그렇다면 다음 코드는 시간복잡도가 O(3n)일까?
n = int(input())
print('1부터 2n까지 3배씩 곱해주어 출력하기')
for i in range(1, 2*n+1):
i*=3
print(i, end=' ')
print('\n\n1부터 n까지 2배씩 곱해주어 출력하기')
for i in range(1, n+1):
i*=2
print(i, end=' ')
상수배를 한다는 것은 숫자가 작다면 큰 차이가 보여지겠지만,
나중에 어마어마하게 커진 입력값의 크기에 의한 영향에 비해 아주 작은 차이이다.
그러므로 시간 복잡도에서 우리는 상수는 무시한다.
O(1) - 상수 시간 (Constant time)
n = int(input())
print('입력받은 수를 3으로 나눈 나머지:', n%3)
n에 0이 들어가던 10억이 들어가던 똑같이 한번 연산한다.
n에 값에 관계 없이 같은 시간이 나오기 때문에 상수 시간인 O(1)이다.
O(logn) - 로그 시간 (Logarithmic time)
def binary_search(target, data):
data.sort()
start = 0
end = len(data) - 1
while start <= end:
mid = (start + end) // 2
if data[mid] == target:
return mid # 함수를 끝내버린다.
elif data[mid] < target:
start = mid + 1
else:
end = mid -1
return None
위의 코드는 이진 탐색 함수이다.
연산을 할때마다 탐색해야 할 자료의 갯수가 1/2로 줄어들기 때문에, O(logn)이다.
ex) 이진 탐색, 퀵 정렬, 병합 정렬, 힙 정렬
O(n) - 선형 시간 (Linear time)
n = int(input())
print('1부터 n까지 2배씩 곱해주어 출력하기')
for i in range(1, n+1):
i*=2
print(i, end=' ')
위의 상수를 무시하는 설명에서 사용했던 예시다.
for문을 통해 n번 연산을 수행하기 때문에 1차함수인 O(n)이다.
입력값 n에 비례해서 연산수가 증가하므로 O(n)이다.
ex) n에 대한 for문
O(n²) - 2차 시간 (Quadratic time)
n = int(input())
for i in range(1,n+1):
for j in range(1,n+1):
print(f'{i} * {j} = {i*j}')
n에 9를 넣으면 구구단을 출력하고,
100을 넣으면 백백단을 출력하는 알고리즘이다.
입력값 n의 제곱에 비례해서 연산수가 증가하므로 O(n²)이다.
ex) n에 대한 이중 for문, 삽입정렬, 버블정렬, 선택정렬 , 면적
O(nm) - 두가지 입력값인 경우
n = int(input())
m = int(input())
for i in range(1,n+1):
for j in range(1,m+1):
print(f'{i} * {j} = {i*j}')
n에 9, m에 9를 넣으면 구구단을 출력하고,
n에 100, m에 9를 넣으면 백구단을 출력하는 알고리즘이다.
입력값 n과 m의 곱에 비례해서 연산수가 증가하므로 O(nm)이다.
ex) n과 m에 대한 이중 for문
O(2ⁿ) - 지수 시간 (Exponential time)
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
가장 좋은 예시인 피보나치수를 재귀함수로 사용할 때이다.
함수를 호출할 때마다 재귀로 함수를 2번씩 호출하기 때문에 2ⁿ에 비례해서 연산 수가 증가한다.
ex) 피보나치 수열
시간 복잡도를 통한 대략적 계산 방법
일반적으로 연산을 1억번 하는데 1초정도 걸린다.
문제를 푼다면 시간 복잡도를 통해 주어진 데이터의 범위에 따라
제한시간에 맞는 알고리즘을 사용해야한다.
| 데이터 수 | 시간복잡도 | 연산 횟수 | 소요 시간 |
|---|---|---|---|
| 10⁸ | n, logn | 1억 | 1초 |
| 10⁶ | nlogn | 1억 | 1초 |
| 10⁴ | n² | 1억 | 1초 |
| 500 | n³ | 1억 | 1초 |
| 20 | n!, 2ⁿ | 1억 | 1초 |
그 외의 Tip
-
Python3으로 시간초과가 났을 경우 PyPy3을 사용하면 통과할 수도 있다!
-
파이썬은 느리지만 코드를 짜기가 쉽고, C계열의 언어는 코드 짜기가 번거롭지만 계산이 빠르다.
-
컴퓨터 공학적 지식 없이 첫 알고리즘 공부라면 파이썬을 추천한다.