SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
| ArXiv | https://arxiv.org/abs/2410.10629 |
|---|---|
| Project Page | https://nvlabs.github.io/Sana/ |
| Github Code | https://github.com/NVlabs/Sana |
| Affiliation | NVIDIA, MIT, Tsinghua University |
- Efficient Linear DiT designReLU 기반 Linear Attention 도입
Mix-FFN Block
- Deep Compression Autoencoder→ 이로 인한 32배 압축 가능으로 연산도 빨라짐

이번에는 SVDQuant의 저자인 Song Han이 또 일을 냈다.
SANA 라는 Diffusion 모델을 NVIDIA에서 제작했는데, 역대급이다.
내가 하려던 On-device 4K Diffusion 연구에도 크게 도움될 것 같아서 읽어보았다.
1. Introduction
지난 1년동안 Diffusion 모델은 text-to-image 연구에서 상당한 진전을 보임.
하지만, 아래와 같이 상업 모델은 파라미터가 매우 커짐 → 높은 학습 및 추론 비용을 초래하여 비용이 많이 들음.
Industry models are becoming increasingly large, with parameter counts escalating from PixArt’s 0.6B parameters to SD3 at 8B, LiDiT at 10B, Flux at 12B, and Playground v3 at 24B.
cloud 뿐만 아니라 edge devices에서도 빠르게 실행되는 고해상도 image generator를 개발할 수 없을까?
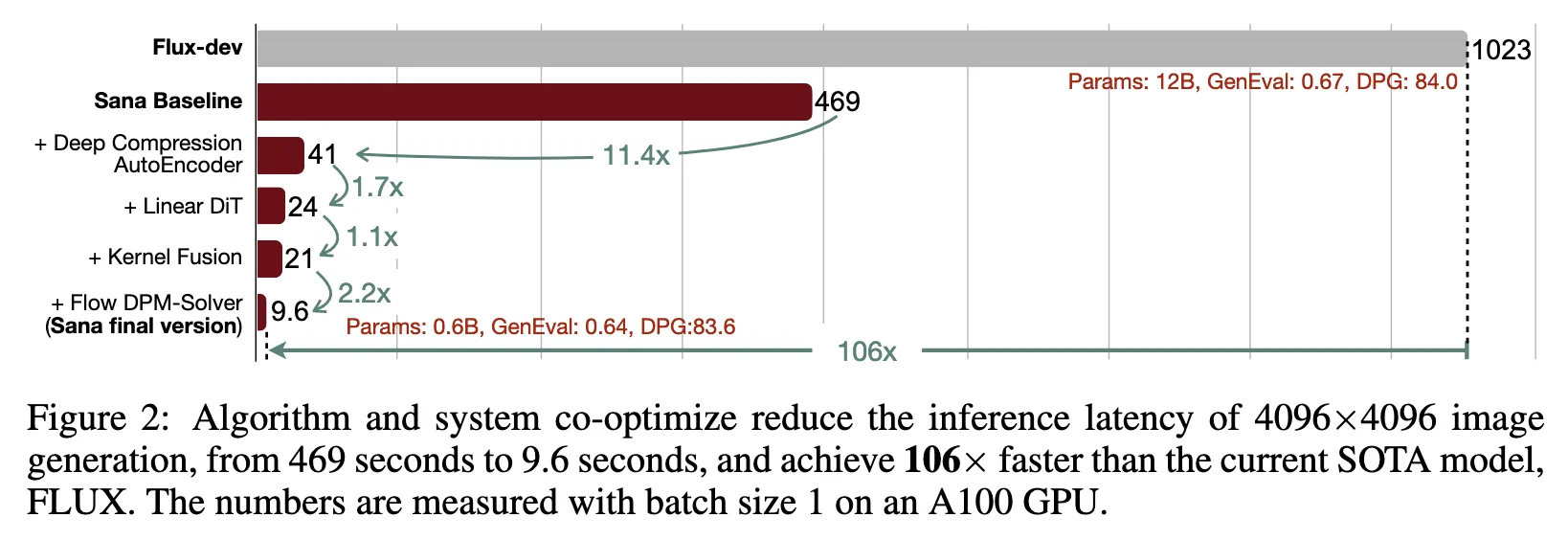
이 논문은 1024 × 1024 ~ 4096 × 4096 범위의 해상도에서 이미지를 효율적이고 비용 효율적으로 훈련하고 합성하도록 설계된 파이프 라인 인 SANA를 제안
Pixart-σ (Chen et al., 2024a)를 제외하고는 4K 해상도 이미지 생성을 직접 탐색하지 못했습니다. 그러나 Pixart-σ는 4K 해상도에 가까운 이미지를 생성하는 것으로 제한되며 (3840 × 2160) 이러한 고해상도 이미지를 생성 할 때 비교적 느립니다. 이 야심 찬 목표를 달성하기 위해 몇 가지 핵심 디자인을 제안합니다.
2. METHODS
2.1 DEEP COMPRESSION AUTOENCODER
2.1.1 PRELIMINARY
원래 diffusion 모델은 이미지 픽셀 공간 (pixel space) 위에서 직접 작동 → 훈련, 추론 둘다 너무 느리고 무거움
Latent Diffusion Models
Autoencoder로 이미지 압축 후 압축된 latent 공간 위에서 diffusion을 돌리자!
→ 8배 압축 사용
여기서
는 latent 채널 수
Diffusion Transformer (DiT)
추가로 latent feature를 Patch 단위로 또 나눠서 처리
패치크기가 PxP 라면 최종적으로 다루는 토큰 개수는
기존 latent diffusion 모델들(PixArt, SD3, Flux 등)은 보통 다음 세팅을 씀
기존처럼 8배 압축만 하면 계산량이 여전히 너무 많음
그래서 SANA는 과감하게 32배 압축(AE-F32)하고, 패치로는 묶지 않음.
2.1.2 AUTOENCODER DESIGN PHILOSOPHY
| 구분 | 기존 (PixArt, Flux) | SANA |
| AE 압축비 | 8배 (F=8) | 32배 (F=32) |
| Patchify (P=2) | O (패치로 묶음) | ✖️ (패치 안 묶음) |
| 최종 Token 수 | 줄였지만 아직 많음 | 훨씬 적음 (16배 감소) |
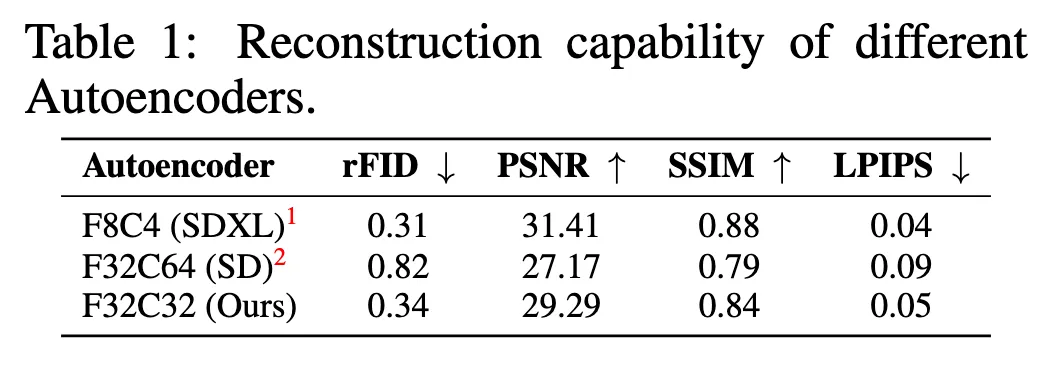
위의 표를 보면 알 수 있듯이 32배 압축하더라도 점수가 크게 떨어지지 않는 모습을 보임
2.1.3 ABLATION OF AUTOENCODER DESIGNS
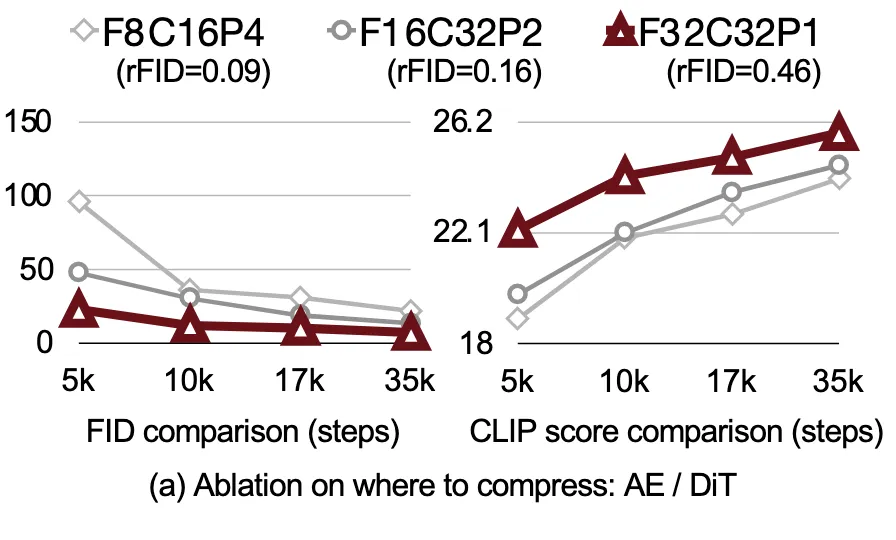
| 설정 | 설명 |
| AE-F8C16P4 | 8배 압축 + 패치 크기 4 |
| AE-F16C32P2 | 16배 압축 + 패치 크기 2 |
| AE-F32C32P1 | 32배 압축 + 패치 사용하지 않음 (SANA) |
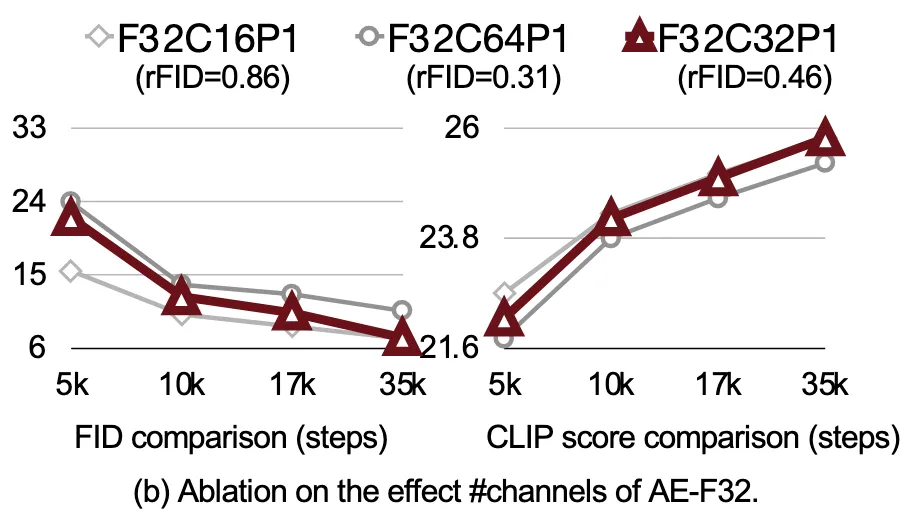
AE-F32C32P1 설정이 가장 뛰어난 성능(FID, CLIP Score)을 기록
Autoencoder가 압축을 전적으로 담당하는 것이 성능 및 훈련 안정성 모두에서 가장 우수
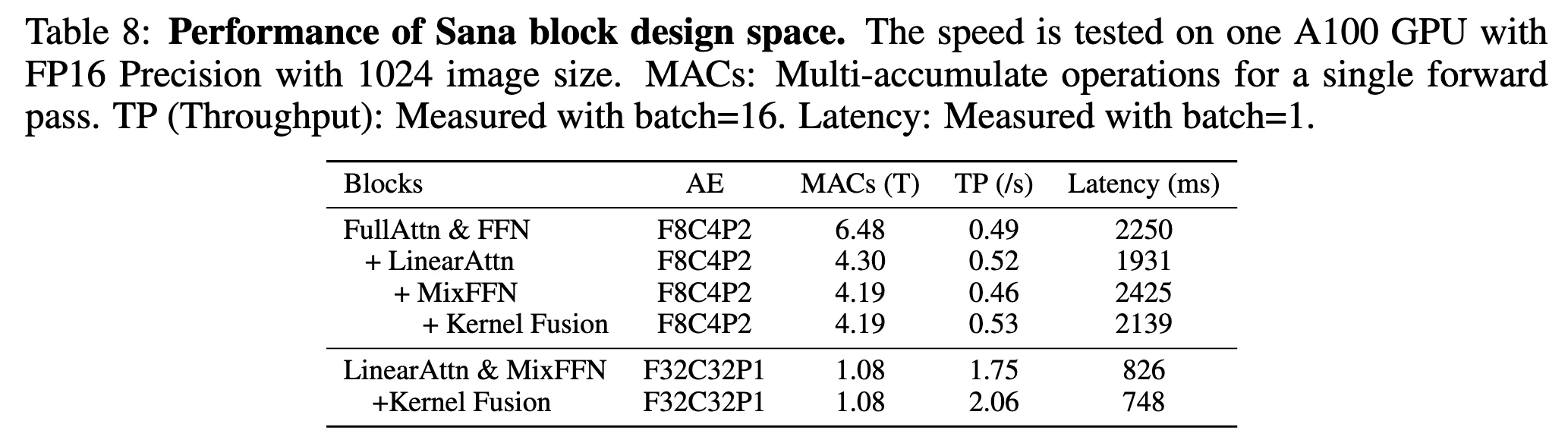
2.2 EFFICIENT LINEAR DIT DESIGN
→ 이때, 기존 연구들은 이 문제를 해결하려고 해상도 낮추거나 Token 수를 줄였음.
ReLU 기반 Linear Attention 도입
기존 Softmax 기반 Attention을 제거하고, ReLU를 이용한 Linear Attention을 채택
Softmax는 모든 Query-Token 조합을 다 계산하기 때문에 O(N²) 복잡도가 발생
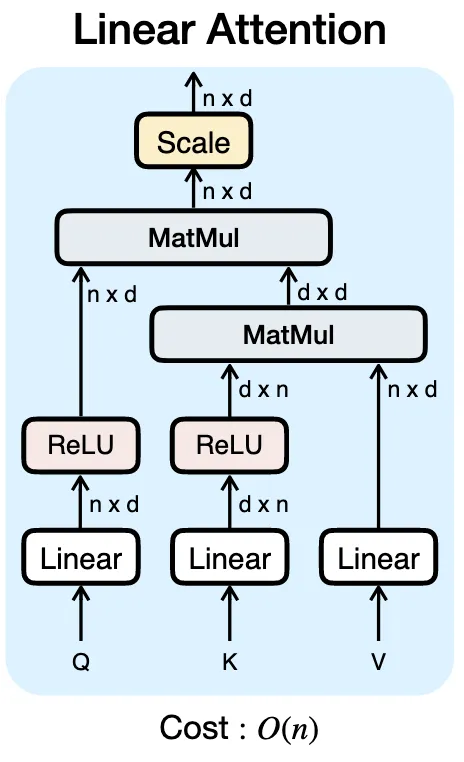
- 각 Key에 ReLU를 적용함: ReLU(K)
- 두 가지 공유 term을 미리 계산
- (dxd matrix)
- (d×1 vector)
- 이후, 각 Query에 대해 이 pre-computed shared term을 재사용하여 Attention을 계산
PixArt도 Linear이랬는데 다른점은?
PixArt에서는 Key와 Value 토큰을 압축하여 연산량을 줄여서 Engineering Optimization으로 O(N)과 비슷하게 하는 방식, SANA에서는 아예 수학적으로 계산량이 O(N)
Mix-FFN Block
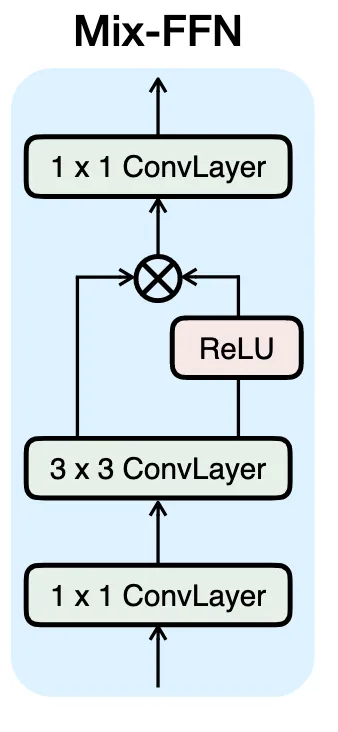
기존 Transformer의 FFN (Feed-Forward Network)은 단순히 2개의 Linear Layer로 구성되어 있었음.
FFN은 전역적인 정보는 잘 처리하지만, 지역적인(local) 디테일 복원에는 약했음.
SANA의 해결책:
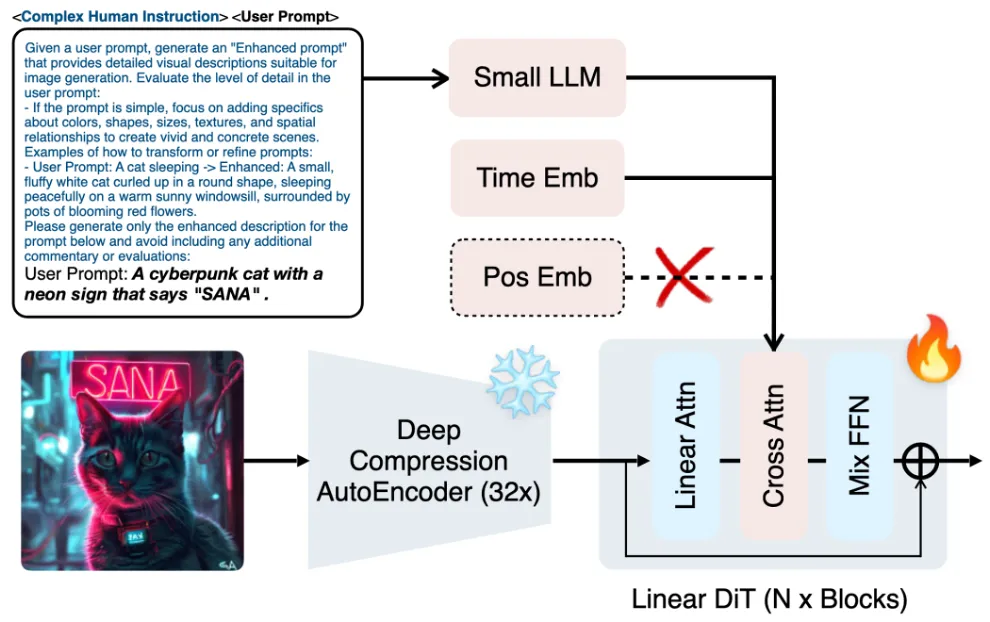
DiT without Positional Encoding (NoPE)
기존 Transformer 구조는 입력 순서를 인식하도록 Positional Encoding을 사용했음.
왜냐면 Transformer는 입력 순서를 구별할 수 없었기 때문에…
하지만 4K 고해상도 latent처럼 토큰 수가 많을 때, Positional Encoding을 계산하고 저장하는 데도 비용이 큼.
SANA에서는 아예 Positional Encoding을 제거함
→ 별도로 위치 정보를 부여하지 않아도 충분히 패턴과 구조를 학습할 수 있음.
결과적으로 품질이 유지되면서 구조가 간단해지고 메모리 연산량이 감소함
Triton Acceleration Training/Inference
Appendix에 추가한다고 되어있는데 아직 관련 내용 없음.
GPT가 알려준 내용
Triton으로 최적화한 결과:
2.3 TEXT ENCODER DESIGN
왜 T5 대신 Decoder-only LLM을 사용하는가?
SANA는 Gemma를 Text Encoder로 사용하기로 채택
| 항목 | 기존 (T5) | SANA (Gemma-2) |
| 모델 구조 | Encoder-Decoder | Decoder-only |
| Reasoning 능력 | 제한적 | 매우 강함 (CoT, ICL 가능) |
| 추론 속도 | 느림 (T5-XXL) | 6배 빠름 (Gemma-2-2B) |
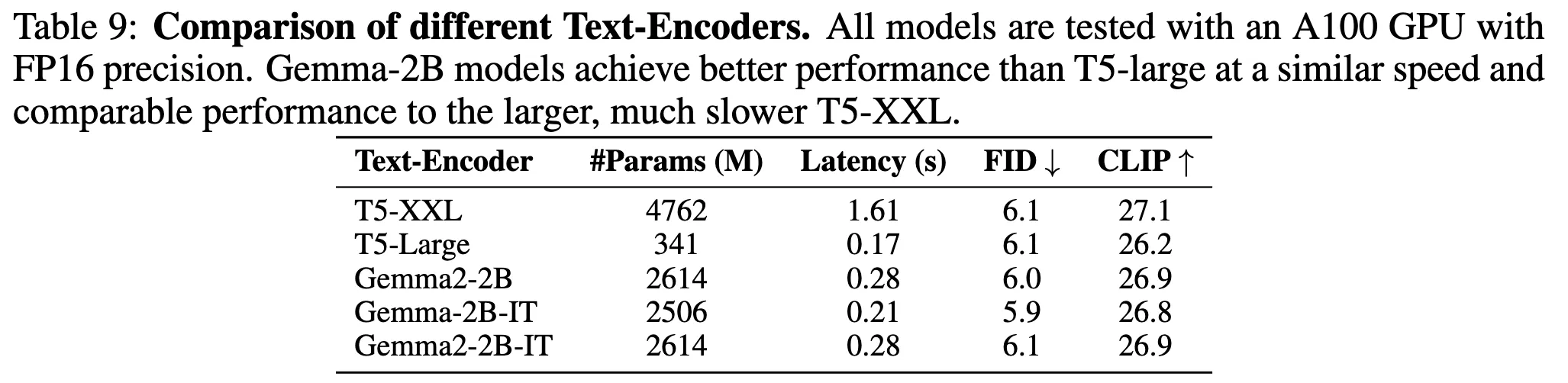
→ 빠른데도 불구하고, CLIP Score와 FID(이미지 품질 지표)에서는 성능이 비슷함
Decoder-only LLM을 Text Encoder로 쓰면서 생긴 문제 해결
Decoder-only LLM (Gemma, Qwen 등)의 텍스트 임베딩은 Variance가 훨씬 큼.
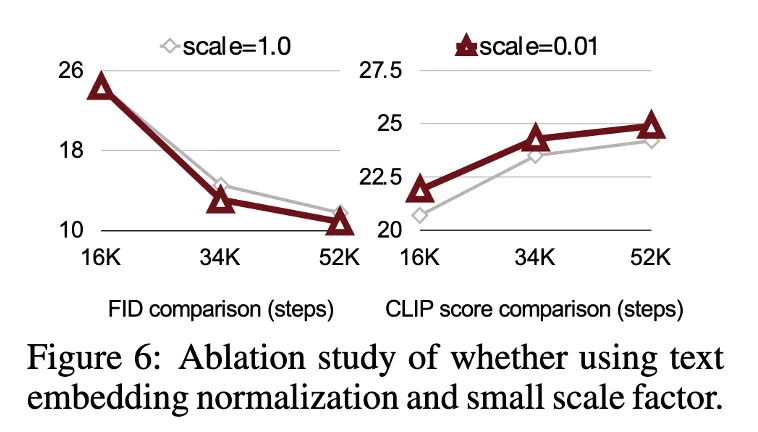
방법 1: RMSNorm 추가
Gemma-2의 텍스트 임베딩 출력에 RMSNorm을 적용
RMSNorm?
방법 2: Learnable Scale Factor 추가
→ 훈련 안정성 확보 + 수렴 속도 향상
Complex Human Instruction Improves Text-Image Alignment
Gemma는 강력한 LLM이지만, 사용자가 짧거나 모호한 프롬프트를 입력하면 (예: "a cat")
LLM이 초점을 잃고 엉뚱한 답변을 할 수도 있음.
→ LLM이 프롬프트에만 집중하게 만드는 추가 지시문이 필요함.
CHI가 그래서 뭔디?
LLM의 In-Context Learning 능력을 활용하여 프롬프트를 주기 전에,
LLM에게 "색상, 크기, 위치 관계 같은 세부 묘사를 추가해라"와 같은 복잡한 명령 세트를 함께 제공하는 것
결과 1

CHI를 적용했을 때, 학습을 처음부터 하든(fresh training)
아니면 기존 모델을 미세 조정(fine-tuning)하든
텍스트-이미지 정렬 성능이 향상
결과 2

짧은 프롬프트(예: "a cat")를 입력했을 때,
CHI가 없으면, 모델이 엉뚱한 이미지를 생성하거나 품질이 불안정해짐.
CHI가 있으면, 모델이 프롬프트에 정확히 맞는 안정적인 이미지를 생성
3 EFFICIENT TRAINING/INFERENCE
3.1 DATA CURATION AND BLENDING
1. Multi-Caption Auto-labelling Pipeline
이미지 하나당 4개의 VLM(Vision-Language Models) 을 이용해 캡션을 생성함.
→ 정확한 캡션 생성 (하나만 쓰는 것보다 오류 줄임)
→ 다양한 표현 확보 (같은 이미지를 여러 관점에서 묘사 가능)
2. CLIP-Score-based Caption Sampler
문제 상황
훈련할 때 어떤 캡션을 선택할지가 문제임.
해결 방법
- 이미지에 대해 생성된 각 캡션의 CLIP 점수(cic_ici)를 계산
- 점수가 높은 캡션일수록 뽑힐 확률이 높게 설정
- Sampling 확률 공식:
여기
실험 결과
3. Cascade Resolution Training
기존 방식
문제점
SANA 방식
latent 공간이 매우 작음 → 연산 부담이 적음.
3.2 FLOW-BASED TRAINING / INFERENCE
Flow-based Training
기존 방식 : noise prediction
→ 노이즈를 맞추는 것이 학습 목표
문제점 : t가 커지면 (Diffusion 마지막 단계에 가까우면) 노이즈가 커져서 예측 불안정
새 방식 : EDM ,RF
noise 대신 data나 velocity(노이즈와 원본 이미지 차이) 예측
EDM : (원본 데이터 예측)
RF : (velocity 예측)
결국 RF를 사용하여 cumulative(누적) error를 줄일 수 있음
Flow-based Inference
기존 : DPM-Solver++
→ required 28-50 steps for high-quality samples
현재 : Flow-DPM-Solver
1.Not predict original data, but velocity
2.substituting the scaling factor αt with 1 − σt
3.time-steps are redefined over the range [0, 1] instead of [1, 1000]
→Generate high-quality samples in 14-20 steps
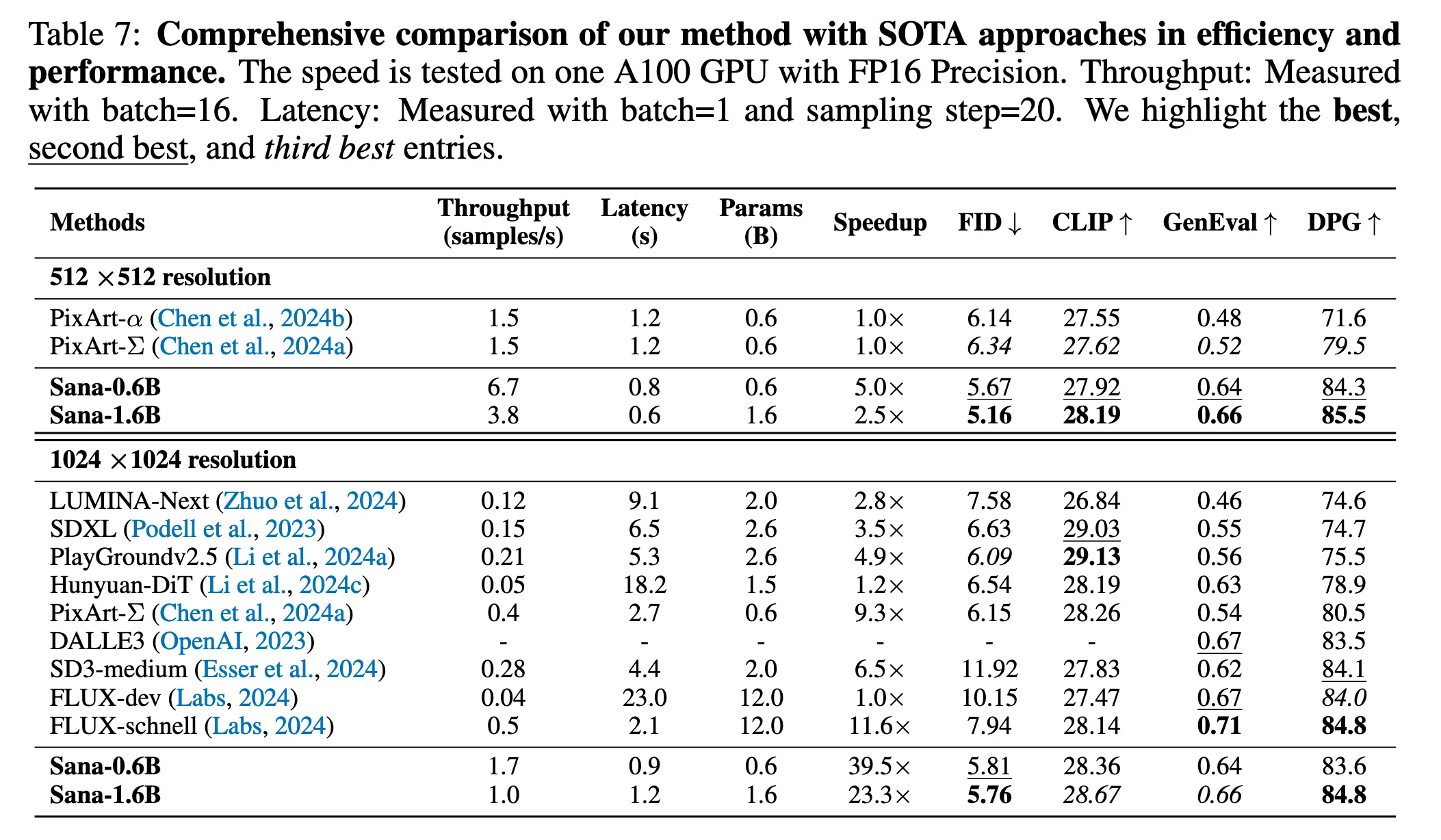
5. Experiments
1. Model Details
Sana-0.6B
Sana-1.6B
2. Evaluation Details
SANA는 총 5가지 대표적인 평가 지표를 사용하여 성능을 평가함.
| 지표 | 설명 |
| FID (Fréchet Inception Distance) | 이미지 품질을 수치로 측정. 낮을수록 좋음 |
| CLIP Score | 이미지와 텍스트 간 의미적 정렬 정도 평가. 높을수록 좋음 |
| GenEval (Ghosh et al., 2024) | 텍스트-이미지 정렬 평가. 총 533개의 프롬프트 사용 |
| DPG-Bench (Hu et al., 2024) | 텍스트-이미지 정렬 정밀도 테스트. 1065개의 프롬프트 사용 |
| ImageReward (Xu et al., 2024) | 인간의 주관적 선호도를 반영한 점수. 100개 프롬프트로 측정 |
3. 평가 데이터셋
Limitation
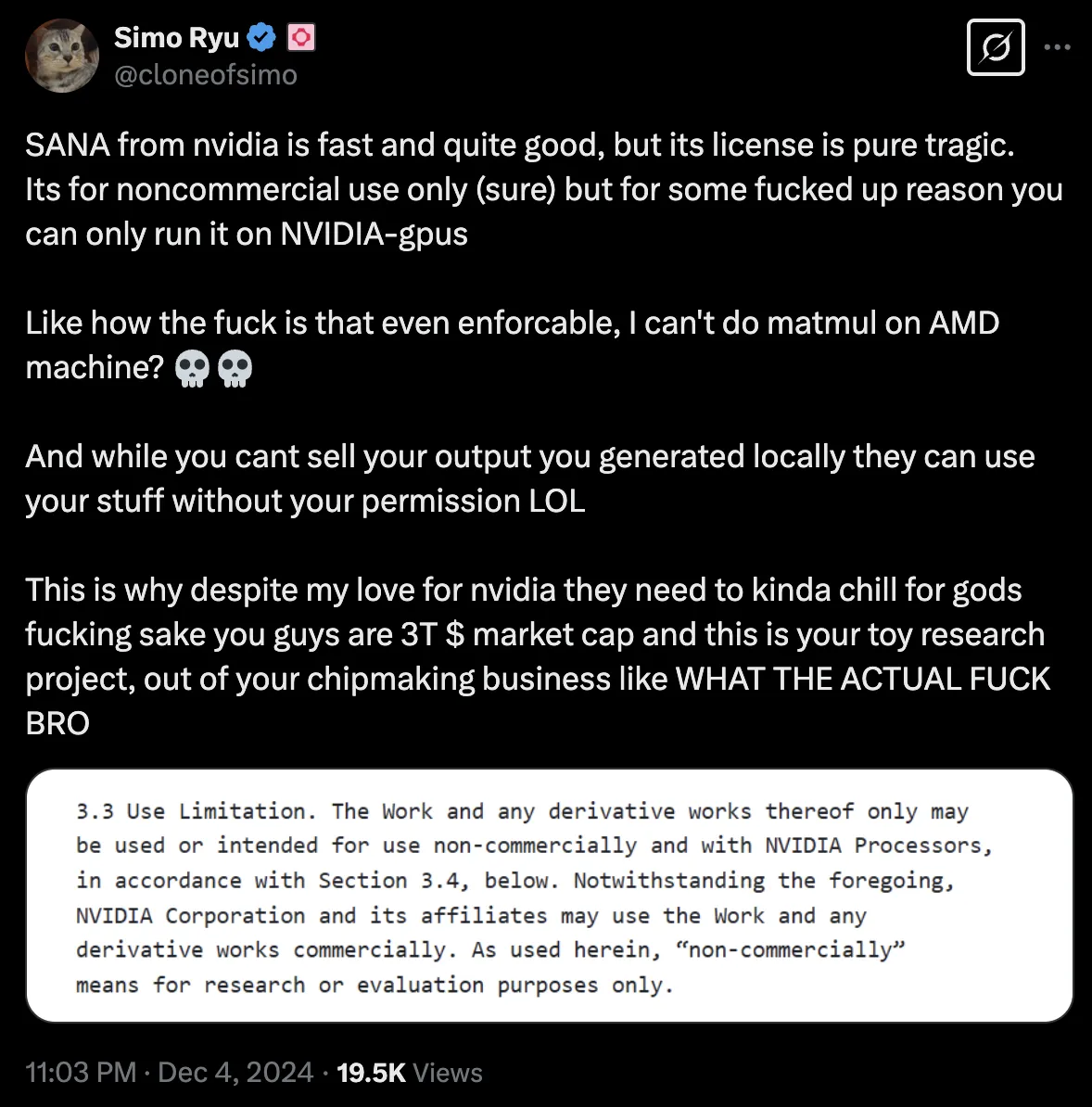
https://x.com/cloneofsimo/status/1864309440356470894?s=46
코드가 전반적으로 NVIDIA칩만을 위해 설계되어
다른 GPU 장비는 물론이고,
Mobile Device에서는 당연히 불가능함.
아무래도 NVIDIA에서 낸 논문이기 때문에 Blackwell chip 홍보 겸 NVIDIA chip에서만 가능하도록 한듯.