PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
| ArXiv | https://arxiv.org/abs/2403.04692 |
|---|---|
| Project Page | https://pixart-alpha.github.io/PixArt-sigma-project/ |
| Github Code | https://github.com/PixArt-alpha/PixArt-sigma |
| Affiliation | Huawei Noah’s Ark Lab, Dalian University of Technology, HKU, HKUST |
2. Related Work
PixArt-α (ICLR 2024 Spotlight)
Stable Diffusion XL (SDXL, 2023)
GigaGAN (Adobe, 2023)
LLaVA (Visual Instruction Tuning, 2023)
DALL·E 3 (OpenAI, 2023)
3. Framework
3.1 Data Analysis
| Data | ||
| Internal-α | 14M | |
| Internal-Σ | 33M | >=1K (33M) real photo 4K (8M) |
| SD v1.5 (open-source) | 2B |
a 때보다 데이터가 많이 늘었고, 4K real photo도 추가함.
하지만 SD v1.5가 2B 데이터인걸 감안하면 아주 제한적인 데이터.
하지만 효과적으로 training함.
이미지의 예술적 품질을 평가하는 Aesthetic Scoring Model(AES)을 사용하여 2M(200만 장)의 고품질 이미지 선별.
→ 해상도가 높아질수록 모델의 충실도(프레셰 초점 거리(FID) [18])와 의미적 정렬(CLIP 점수)이 향상
Better Text-Image Alignment
➡ 텍스트 프롬프트(설명)와 생성된 이미지가 얼마나 일치하는지
즉, 사용자가 입력한 텍스트(prompt)와 모델이 생성한 이미지가 얼마나 정확하게 대응하는지를 평가하는 개념
PixArt-α 는 LLaVa를 사용하였고, PixArt-Σ는 Share-Captioner 사용
| 항목 | LLaVA | Share-Captioner |
| 기반 모델 | CLIP + LLaMA | GPT-4V (GPT-4 with Vision) |
| 텍스트 생성 | 비교적 단순 | 더 길고 세밀한 설명 |
| 정확도 | 가끔 환각 문제 발생 | 더 높은 정확도 |
| 이미지 디테일 반영 | 제한적 (단순 설명) | 더 정밀한 객체 및 관계 설명 |
| 캡션 품질 | 일반적인 설명 수준 | 고품질, 구체적인 묘사 가능 |
다음과 같은 환각 (Hallucinations)가 발생했었음

| 항목 | PixArt-α | PixArt-Σ |
| 텍스트 해석 길이 | 120 토큰 | 300 토큰 (2.5배 증가) |
| 캡션 생성 모델 | LLaVA (단순함) | Share-Captioner (정확한 설명) |
| CLIP Score | 0.2787 | 0.2797 (향상됨) |
| 환각 문제 해결 | 일부 존재 | 환각 감소 (더 정밀한 캡션 사용) |
➡ PixArt-Σ는 더 긴 문장을 해석하고, 더 정교한 캡션을 사용하여 텍스트-이미지 정렬 성능을 높였음.
➡ Share-Captioner를 사용하여 텍스트와 이미지 간 정보 일치도를 개선함.
평가 데이터셋 구성 (High-Quality Evaluation Dataset)
- Fréchet Inception Distance (FID) → 이미지 품질 평가
- CLIP Score → 텍스트-이미지 정렬 성능 평가

3.2 Efficient DiT Design
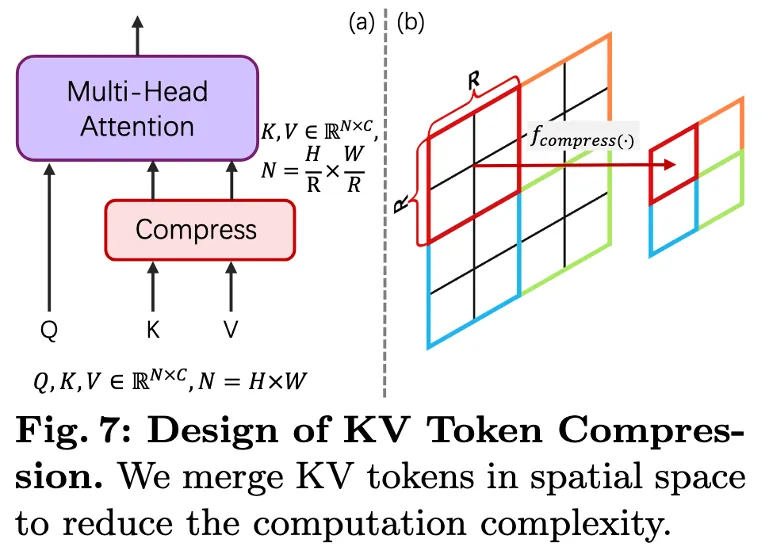
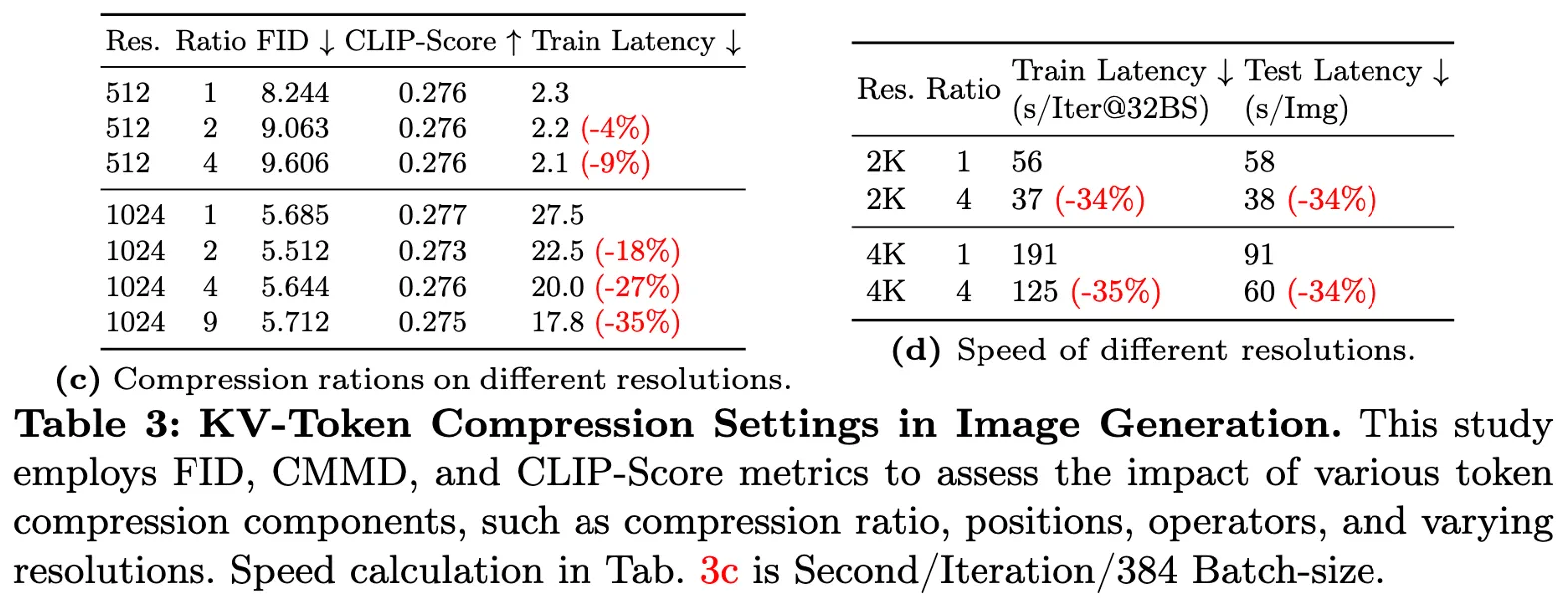
Key-Value (KV) Token Compression 기법
🔹 기존 Attention 연산 문제
🔹 PixArt-Σ의 KV Token Compression 방식
핵심 효과
3.3 Weak-to-Strong Training Strategy
PixArt-Σ의 Weak-to-Strong Training은 기존 모델의 가중치를 활용하여 빠르게 적응하도록 설계됨.
이 과정에서 3단계의 학습 전략이 적용됨.
(1) VAE 적응 (VAE Adaptation)
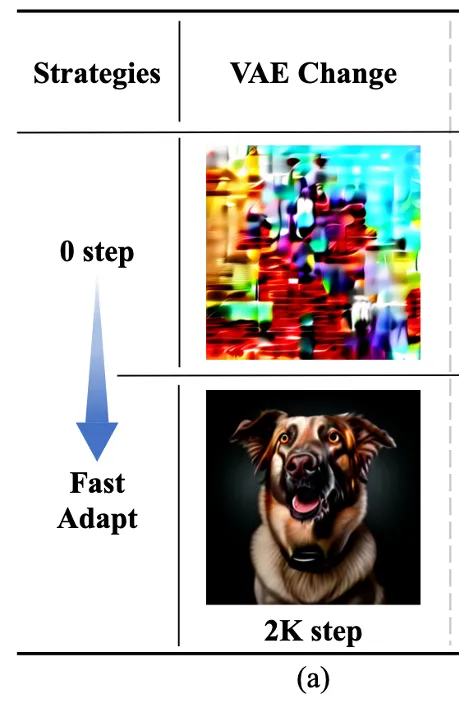
(2) 해상도 업그레이드 (Resolution Upscaling)
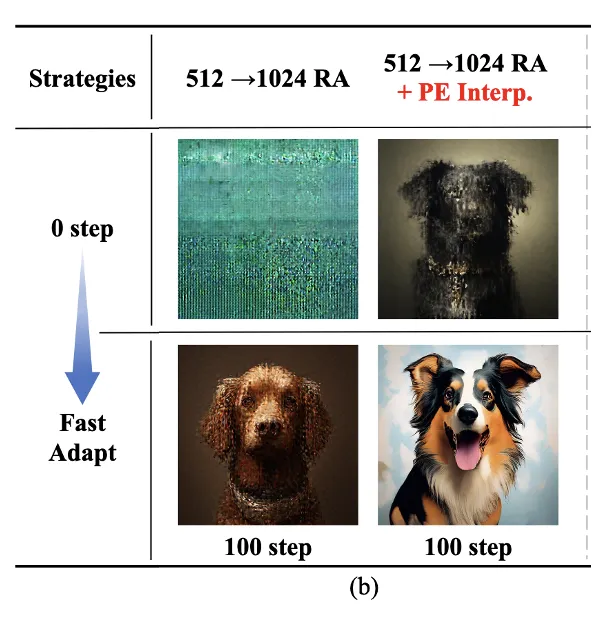
(3) KV Token Compression 도입 (연산 최적화)
평균 연산(Averaging) 기반 초기화
1/R² 로 설정하여, 기존 정보를 최대한 유지하면서 부드럽게 전환함.
결과적으로, 기존 PixArt-α 대비 적은 연산량과 빠른 학습으로 4K 이미지 생성이 가능해짐.

4. Experiment
4.1 Implementation Details (구현 세부사항)
1. 모델 구성
텍스트 인코더
VAE (Variational Autoencoder) 적용
기반 모델
KV Token Compression 적용
2. 학습 환경 및 하드웨어
훈련 GPU 환경
최적화 알고리즘
Position Embedding Interpolation (PE Interp.) 적용
3. 학습 데이터 및 훈련 과정
훈련 데이터셋
훈련 과정
학습 비용 절감
4.2 실험 결과
1. 이미지 품질 비교 (Qualitative Evaluation)
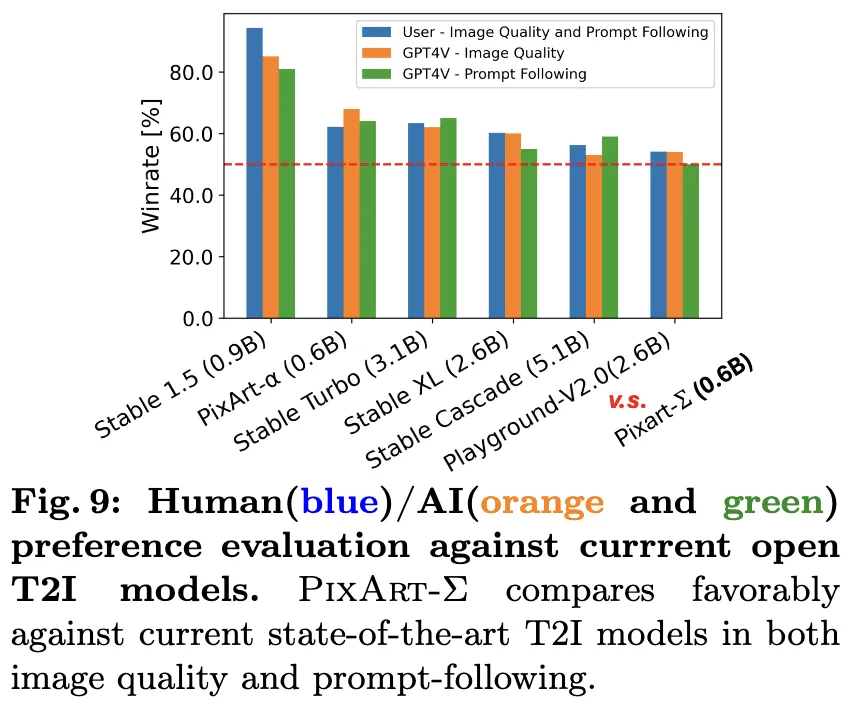
PixArt-Σ는 포토리얼리즘(Photorealism), 디테일 수준, 스타일 다양성 측면에서 이전 모델보다 개선됨.
아래와 같은 모델들과 비교됨:
PixArt-α vs PixArt-Σ
| 항목 | PixArt-α (기존) | PixArt-Σ (개선) |
| 최대 해상도 | 1K (1024×1024) | 4K (3840×2160) 지원 |
| 연산량 최적화 | 없음 | KV Token Compression 적용 (연산량 34% 감소) |
| VAE 모델 | 기본 VAE | SDXL VAE로 변경 (고품질 이미지 생성 가능) |
| 학습 전략 | 일반 학습 | Weak-to-Strong Training (기존 모델 활용하여 빠르게 학습) |
| 텍스트 길이 | 120 토큰 | 300 토큰으로 확장 (더 정밀한 텍스트-이미지 정렬 가능) |
| 훈련 비용 | 높음 | 기존 대비 GPU 비용 9%로 절감 |
PixArt-Σ vs. MobileDiffusion 비교표
| 항목 | PixArt-Σ | MobileDiffusion | 비교 |
| 목표 | 4K 초고해상도 이미지 생성 | 모바일에서 실시간 생성 가능하도록 최적화 | PixArt-Σ는 초고해상도 생성, MobileDiffusion은 On-Device 최적화 |
| 모델 구조 | Diffusion Transformer (DiT) 기반 | Latent Diffusion + Optimized UNet | PixArt-Σ는 Transformer 기반, MobileDiffusion은 UNet 기반 |
| 텍스트 인코더 | Flan-T5-XXL (300 토큰까지 가능) | CLIP-ViT/L14 (텍스트-이미지 효율성 극대화) | PixArt-Σ가 더 긴 텍스트 입력 가능, MobileDiffusion은 가벼움 |
| 이미지 해상도 | 4K (3840×2160) 직접 생성 가능 | 512×512 (On-Device에서 빠르게 생성) | PixArt-Σ는 초고해상도, MobileDiffusion은 저해상도 최적화 |
| KV Token Compression | Self-Attention 연산량 34% 절감 (R=2, R=4 적용) | 사용하지 않음 | PixArt-Σ는 4K 최적화, MobileDiffusion은 경량 모델이라 필요 없음 |
| 모델 크기 | 0.6B 파라미터 (SDXL: 2.6B 대비 작음) | 386M (SD-1.5 대비 55% 축소) | MobileDiffusion이 더 작음 |
| VAE (Autoencoder) | SDXL VAE 사용 (고품질 이미지 복원 가능) | 경량화된 VAE 적용 (512px에서 최적화됨) | PixArt-Σ는 품질 우선, MobileDiffusion은 속도 우선 |
| 해상도 업스케일링 기법 | PE Interpolation (기존 모델을 고해상도로 자연스럽게 변환) | 512px 고정 (Upscaling 없음) | PixArt-Σ는 해상도 확장 가능, MobileDiffusion은 저해상도 고정 |
| 연산 최적화 | Weak-to-Strong Training (기존 모델 재사용으로 학습 비용 절감) | Transformer 블록 제거 + Convolution 기반 최적화 | PixArt-Σ는 기존 모델 활용, MobileDiffusion은 경량화 모델 |
| On-Device 실행 가능 여부 | 불가능 (고성능 GPU 필요) | 가능 (iPhone 15 Pro에서 0.2초 생성) | MobileDiffusion이 훨씬 가벼움 |
| 학습 데이터 크기 | 33M (4K 데이터 포함, SD v1.5의 1.65%) | 150M (모바일 최적화된 데이터) | MobileDiffusion이 더 큰 데이터셋 사용 |
| 이미지 품질 평가 (FID Score) | 8.23 (PixArt-α 대비 개선됨) | 11.67 (1-step) / 8.65 (50-step DDIM) | PixArt-Σ가 품질 우수, MobileDiffusion은 속도 최적화 |
| 텍스트-이미지 정렬 (CLIP Score) | 0.2797 (PixArt-α 대비 향상됨) | 0.320 (1-step) / 0.325 (50-step DDIM) | MobileDiffusion이 더 나은 정렬 성능 |
| 생성 속도 | 느림 (4K 생성에 고사양 GPU 필요) | 0.2초 (iPhone 15 Pro에서 실시간 생성) | MobileDiffusion이 훨씬 빠름 |