IO similarity가 높다 → 입력과 출력이 거의 같음 → 모듈이 큰 변화 없이 데이터를 전달 → 중요도가 낮음
IO similarity가 낮다 → 입력과 출력이 많이 다름 → 모듈이 적극적으로 변환 → 중요도가 높음
IO Similarity와 중요도의 관계 검증
1차 실행: 각 레이어의 IO similarity를 측정하여 프로파일링.
2차 실행: 특정 similarity 값을 기준으로 레이어를 선택적으로 스킵(skip)하고 성능(GPT score) 확인.
결과:
LeastSkip: IO similarity가 낮은 레이어를 스킵 → 성능 급격히 하락 (1개만 스킵해도 점수 < 1.0).
MostSkip: IO similarity가 높은 레이어를 스킵 → 1, 3, 5개 스킵 시에도 점수 8.9, 6.1, 4.2 유지.
→ IO similarity가 높을수록 스킵해도 성능 손상이 적다.
Existing Layer-wise Skipping Strategies
Early Skipping
항상 앞쪽 몇 개 레이어를 고정적으로 스킵.
장점: 배치(batch) 연산 호환성 좋음.
단점: 앞부분이 중요한 경우 성능 손실 가능.
Periodic Skipping
일정 간격으로 중간 레이어를 스킵 (예: 4개마다 1개 스킵).
장점: 배치 연산 가능.
단점: 레이어 중요도의 변동성을 반영하지 못함.
Early Exit
각 레이어 계산 후 조건(예: confidence)이 충족되면 뒤 계산 생략.
장점: 불필요한 연산 절약.
단점: 중요한 뒷부분 레이어를 건너뛸 위험, classifier 학습이나 모델 파인튜닝 필요.
Motivation
기존 레이어 스키핑 전략들이 장문 맥락 추론에서 한계가 있는 이유
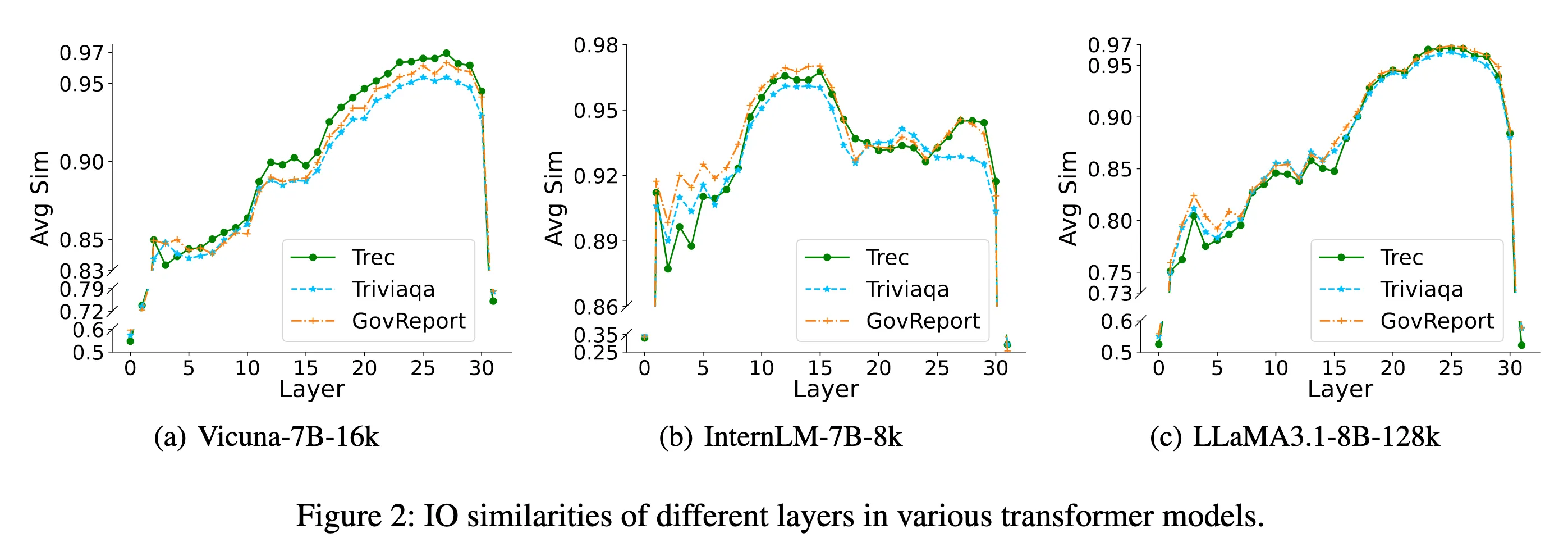
Observation 1: The layer importance distribution exhibits significant variation across diverse models. 모델에 따라 레이어 중요도 분포가 크게 다르다.
기존 layer-wise skipping 기법은 “항상 같은 위치의 레이어”를 건너뛰는데,
이렇게 하면 모델별 중요도 패턴 차이를 무시하게 돼서 적응성이 떨어짐.
따라서 모델별로 맞춤형(Adaptive) 스킵 전략이 필요.
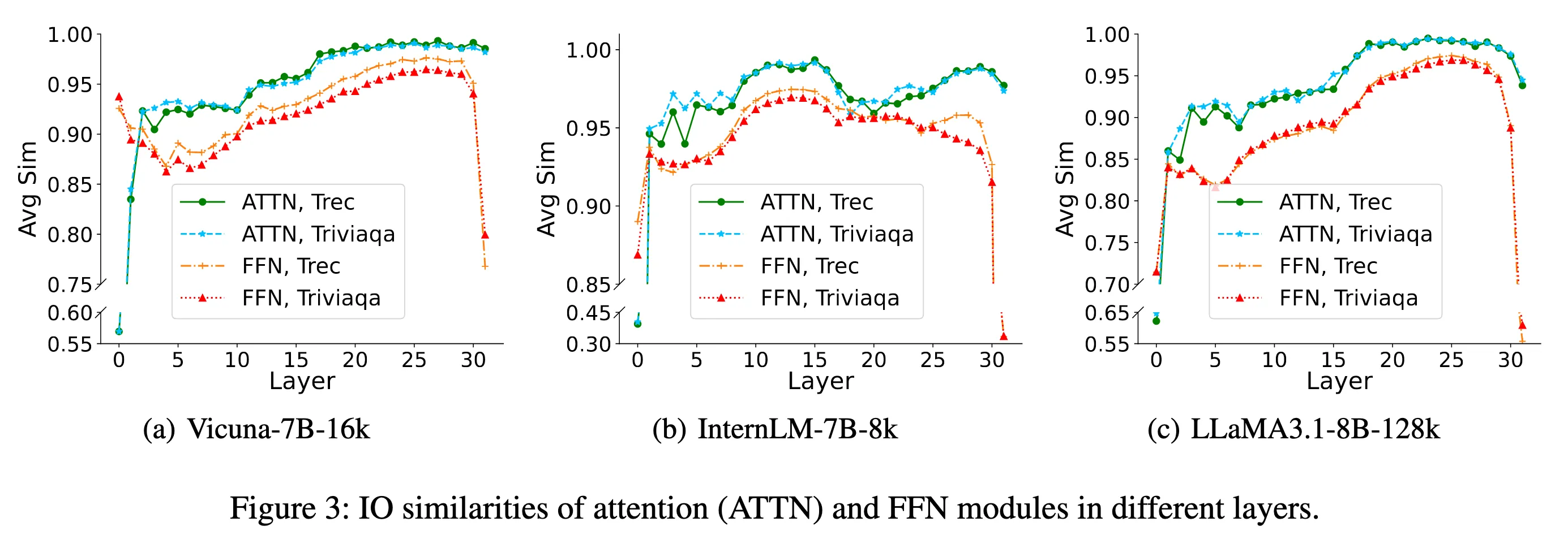
Observation 2: The importance distributions of attention and FFN modules are different. 어텐션(Attention)과 FFN(Feed-Forward Network) 모듈의 중요도 분포가 서로 다르다.
Transformer 레이어는 보통 Attention sublayer와 FFN sublayer로 구성됨.
Attention sublayer와 FFN sublayer가 뭐야?
Attention sublayer:
문장 속 단어들이 서로를 얼마나 참고해야 하는지 계산하는 부분
→ "이 단어가 저 단어와 얼마나 관련 있는지" 점수를 매기고, 중요한 정보에 더 집중하도록
FFN (Feed-Forward Network) sublayer:
Attention에서 모아온 정보를 각 단어별로 따로 가공하는 작은 신경망
→ "집중해서 모은 정보"를 더 복잡하게 변형하고, 다음 단계로 넘겨줌
이 둘의 IO similarity를 따로 분석해 보니 분포가 다르게 나옴.
Attention: 최고 IO similarity가 거의 0.97으로 높고, 값이 서로 비슷하게 모여 있음.
FFN: 최고 IO similarity가 0.95 정도이고, 값이 퍼져 있음.
→ Attention은 FFN보다 스킵할 후보가 많음
→ 기존 방법처럼 레이어 전체를 한 번에 스킵하는 건 비효율적이고,
sublayer 단위(Attention, FFN 각각)로 따로 스킵 여부를 결정하는 게 더 효과적임.
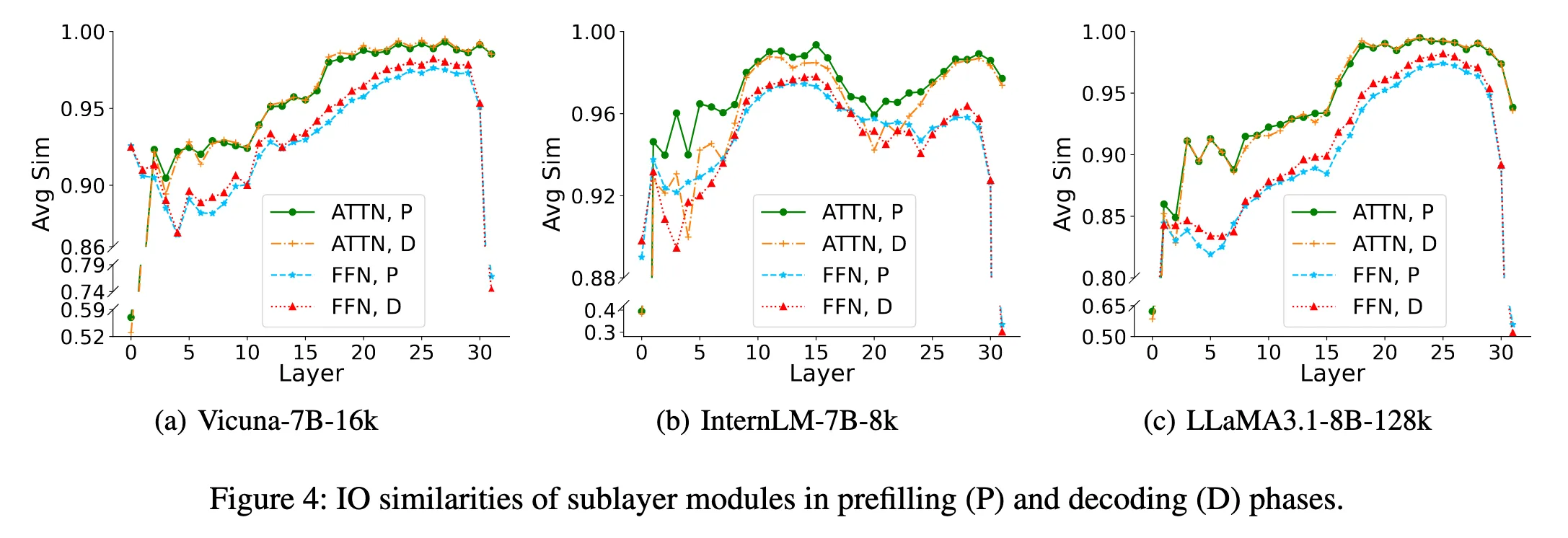
Observation 3: The importance distribution of sublayers in the prefilling and decoding phases have similar trends but different fluctuation degrees. 프리필링과 디코딩 단계에서 서브레이어 중요도 분포의 경향이 유사하지만, 변동 정도는 다르다.
Prefilling: 처음 문맥을 읽어들이는 단계.
Decoding: 토큰을 하나씩 생성하는 단계.
두 단계에서 Attention과 FFN의 IO similarity 변화를 비교:
전체적인 추세는 비슷 → 두 단계에서 비슷한 스킵 전략을 공유할 수 있음.
하지만 FFN sublayer는 IO similarity가 Decoding 단계에서 Prefilling 때보다 높음
→ Decoding 단계에서 FFN sublayer를 더 많이 스킵해도 성능 영향이 적을 가능성이 큼.
Methodology
Sublayer Skipping during Prefilling with Offline Importance Learning
왜 Prefilling 단계에서 스킵이 중요한가?
Prefilling은 긴 입력을 처음 읽는 단계라서:
TTFT (Time To First Token)가 길어짐
KV 캐시 사용량이 많음
모델마다 IO similarity 분포가 달라서, 고정된 레이어 스킵은 최적이 아님.
문제: Prefilling 시작 전에는 중요도에 대한 사전 정보가 없음 → adaptive skipping이 어려움.
Insight
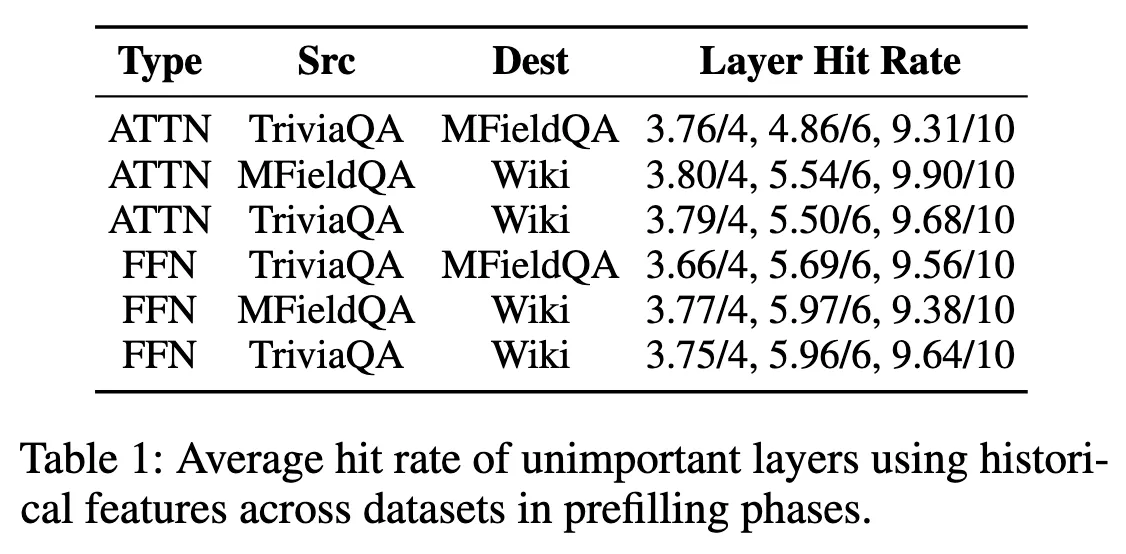
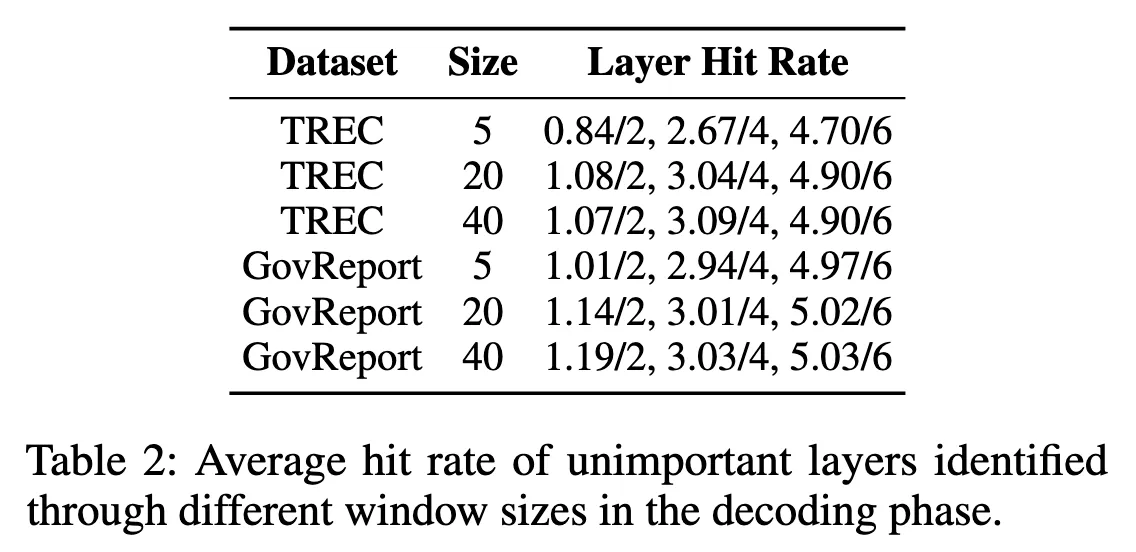
hit rate = unimportant sublayer(= skip target)를 얼마나 잘 맞췄는지 정확도
skip한 sublayer 개수 : 4, 6, 10
그 중에서 얼마나 일치하게 선택되었는지(hit)를 평균 : 3.76, 4.86, 9.31
여러 데이터셋과 LLaMA3.1-8B-128k 모델로 Prefilling IO similarity를 측정
→ 한 데이터셋에서 측정한 평균 IO similarity로 다른 데이터셋에서 스킵 대상을 예측해도 Hit Rate가 높음
Prefilling에서 과거 IO similarity → 현재 스킵 대상 예측이 가능하고, 데이터셋 간 공유도 가능.
Offline Importance Learning Workflow
데이터 수집
여러 개의 inference task(프롬프트)를 준비
각 task는 길이가 다를 수 있고, 모델에는 M개의 transformer 레이어(각각 attention + FFN sublayer)가 있음
각 sublayer(예: attention 1, FFN 1, attention 2, FFN 2, …)별로 입력 벡터 vs 출력 벡터의 유사도(IO similarity)를 측정
모든 task의 토큰마다 값을 모아 평균 IO similarity를 구함 → 이게 “얼마나 덜 중요한지”를 알려줌
하지만 FFN sublayer는 Decoding에서 IO similarity가 더 높음 → 즉, 덜 중요한 경우가 많으니 더 많이 스킵 가능.
Insight
Decoding이 시작될 때, 처음 몇 개 토큰의 IO similarity만 측정해도 이후 생성에서 중요한 sublayer를 잘 예측 가능
실험 (LLaMA3.1-8B-128k)
hit rate = unimportant sublayer(= skip target)를 얼마나 잘 맞췄는지 정확도
초기 window size를 늘릴수록 hit rate가 올라가다 어느 지점 이후 거의 일정.
→ 굳이 모든 토큰을 분석할 필요 없이, 초반 P개의 토큰만 보고 결정해도 충분.
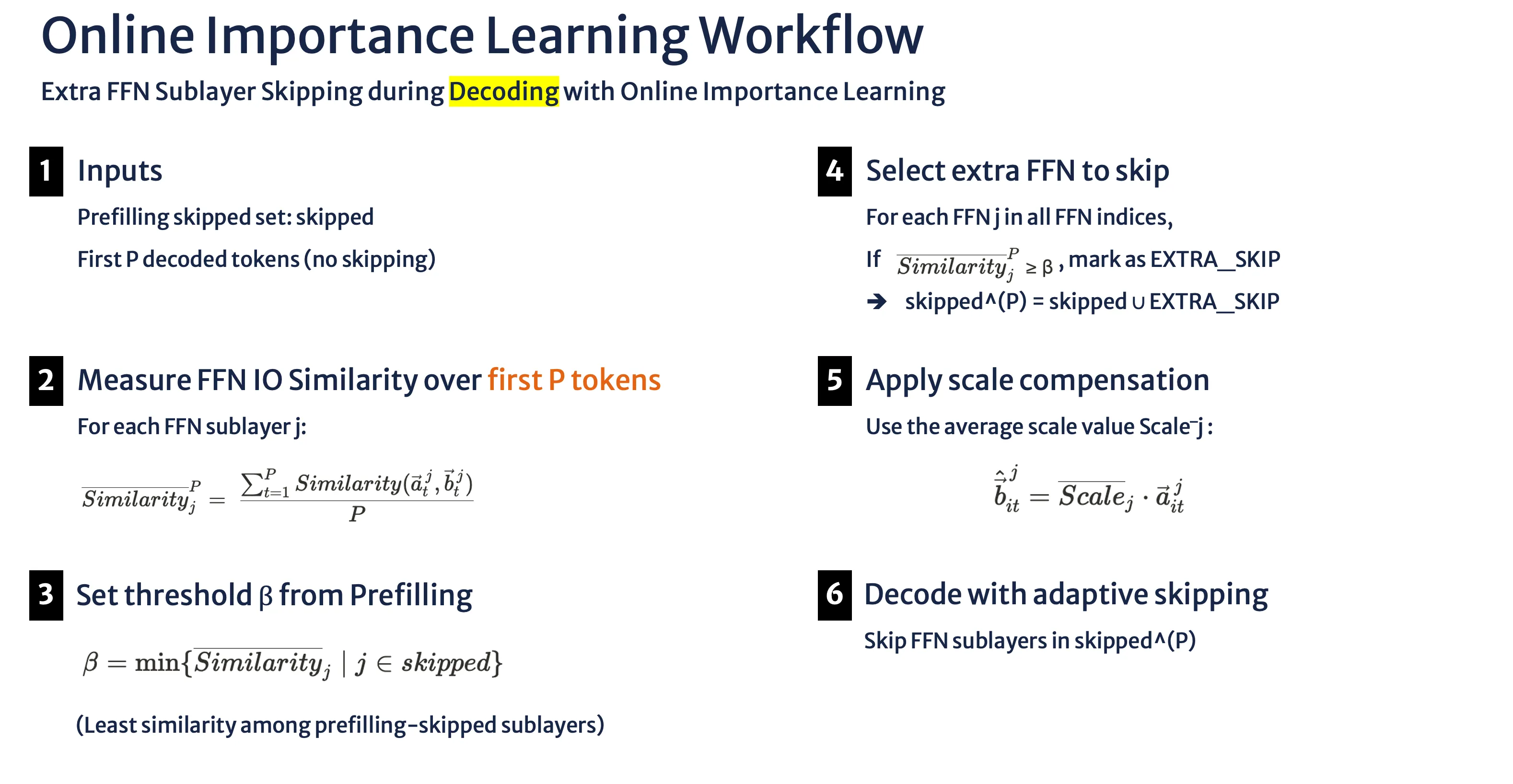
Online Importance Learning Workflow
Input
Prefilling에서 이미 정한 “스킵 후보 집합(skipped)”
Decoding 초반 P개 토큰
초기 윈도우로 FFN 중요도 측정
각 FFN 서브레이어 j에 대해, 처음 P개의 디코딩 토큰에 대한 IO similarity 평균을 계산
SimilarityjP=P∑t=1PSimilarity(atj,btj)
ajt = 입력 벡터, bjt = 출력 벡터
Prefilling 결과와 비교
Prefilling에서 스킵된 sublayer들의 similarity 중 최소값을 β로 설정
“이 값 이상이면 ‘덜 중요한 축’에 속하므로, 디코딩에서도 추가로 스킵해도 괜찮다”
β=min{Similarityj∣j∈skipped}
index: 모든 FFN sublayer 인덱스 집합.
skipped: Prefilling에서 이미 스킵하던 sublayer 집합.
추가 FFN 스킵 선별
모든 FFN 서브레이어 인덱스 집합을 훑으면서 SimilarityjP ≥ β 인 FFN sublayer를 찾기
최종 스킵 집합 생성
Prefilling에서 스킵한 sublayer + 추가로 찾은 FFN sublayer를 합쳐 최종 스킵 집합 완성하기
skipped^(P) = skipped ∪ EXTRA_SKIP
보정(Scale Compensation)
Prefilling에서 미리 구해둔 평균 스케일 값 Scale‾j 를 이용해 입력 벡터를 보정
b^itj=Scalej⋅aitj
추가 가속: Prefilling만 썼을 때보다 더 많은 FFN을 스킵 → 더 큰 속도 향상
성능 유지: 초기 토큰으로 추정하기 때문에 성능 저하를 최소화
실시간 적응: 현재 문맥(context)에 맞춰 동적으로 결정
→ Decoding 초기에 한 번 더 업데이트해서, 덜 중요한 FFN을 건너뛰는 방식
Experiments
Setting
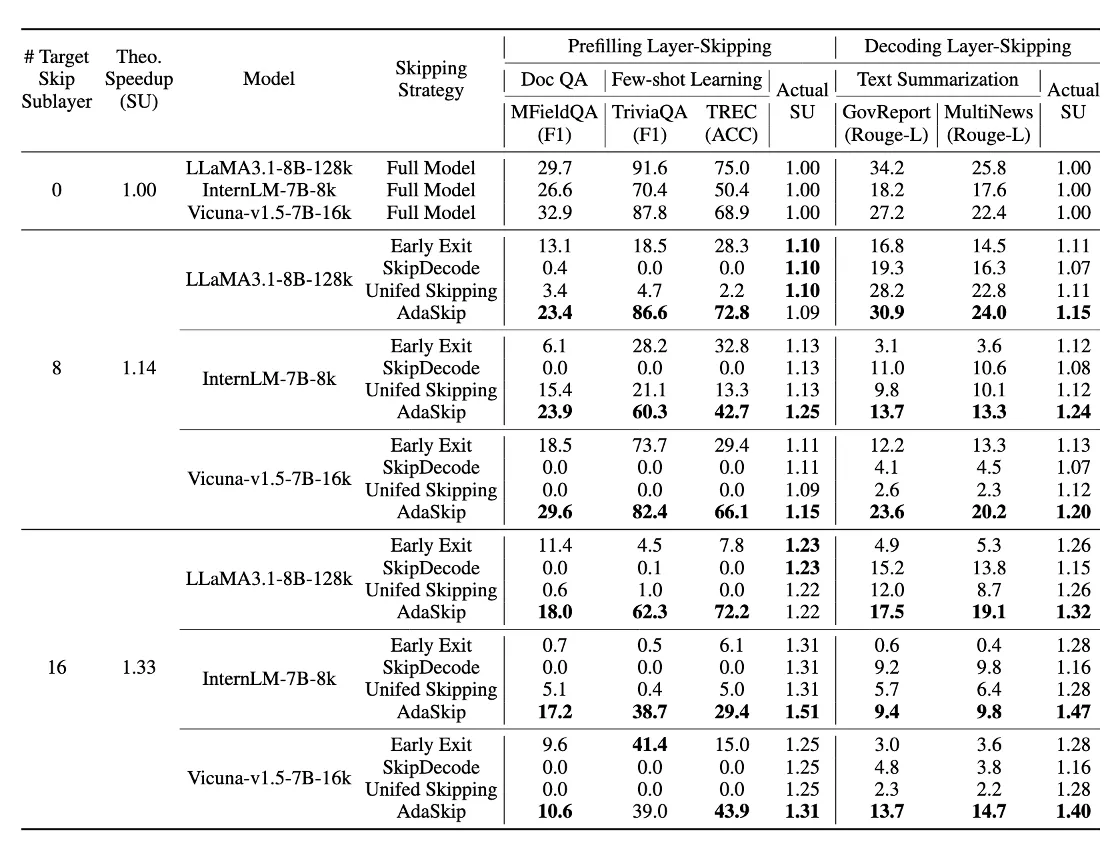
MFieldQA, TREC, TriviaQA → 작은/중간 크기 데이터셋 → 세부 분석용 (ATTN vs FFN 별 hit rate 등)
GovReport, MultiNews → 긴 문맥 요약 데이터셋 → End-to-End 가속 실험용 (실제 성능 + 속도)
Hardware: NVIDIA A100 GPUs (80GB)
KV cache enabled
Prefilling phase에서 acceleration ratio α는 얼마나 많은 sublayer가 skip되는지 보고 결정
Decoding phase online learning에서 첫 토큰 개수는 중요도 보고 추정함 (P = 20, 50, 100)
Results of Prefilling Tasks, Decoding Tasks
F1 : QA같은거에서 정밀도, 재현율 조화평균
ACC : 분류 문제에서 정확도
Rouge-L : 생성 태스크에서 참조 요약과 모델 출력 간의 longest common subsequence 기반 유사도
SU (Speedup) : 기존 대비 속도 향상비율
실제 Speedup는 왜 AdaSkip이 다른 skip 보다 빠를까??
→ 진짜 쓸모없는 sublayer만 골라내 건너뜀 → 더 많은 연산 절약 + 성능 유지
“AdaSkip achieves superior speedup compared with the state-of-the-art skipping strategies, as it adaptively skips the most unimportant sublayers in both prefilling and decoding phases without requiring additional training.”
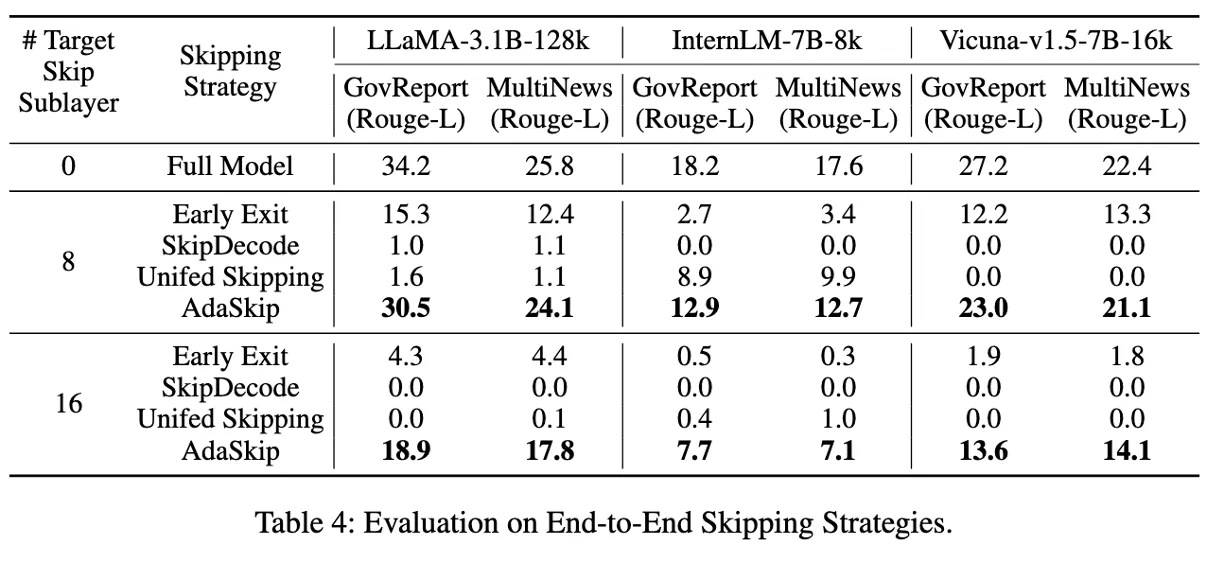
Results of End-to-End Testing
실제로 전체를 실행해도 AdaSkip이 정확도가 높음
Limitation & Future Work
Prefilling 단계에서 사전 데이터가 필요함
처음 실행할 때는 어떤 레이어를 건너뛸지 알 수 없어서 과거 데이터를 기반으로 예측해야 하는 구조.
→ Prefilling에서 더 정교한 zero-shot layer importance predictor 설계
모델·데이터셋 특화 적응성 문제
완전히 새로운 모델이나 도메인에 적용할 때는 아직 한계가 있다
→ Dataset 간 transfer를 넘어 cross-model generalization까지 확장
Not adaptive parameter α (acceleration ratio), P (online learning window size)
실험자가 α와 P를 고정해서 설정해야 함 → 데이터셋이나 태스크가 바뀌면 최적값이 달라짐
→ 모델이 스스로 α와 P를 상황에 맞게 조정할 수 있는 메커니즘 개발
(reinforcement learning, Bayesian optimization, online feedback loop 등)
→ 태스크 난이도나 문맥 길이에 따라 dynamic하게 skip ratio를 조절 → 더 범용적이고 안정적인 성능 확보.
Q&A
논문 Presentation 발표 중 제대로 답변 못한 Q&A
GPT Score
강력한 평가자 모델(GPT-4, Claude, Gemini 등)을 불러와서
문제와 후보 답변을 같이 제시
평가 모델이 어느 쪽이 더 낫다고 판단하거나 점수 매기기
→ 사람이 직접 평가하는 것보다 빠르고 일관성 있음
Skip 방법은 이전 결과가 필요할텐데 어떻게 하는거지?
Early Exit은 종료하는거니까 상관 없는데, Skip 방법은 이전 결과가 필요할텐데…
이 논문에서 Scaling 한다는 것을 알고 있었어서, 그게 일반적인건지 이 논문에서 도입한건지 확실하지 않았었는데, 이 논문에서 도입한 거였다
Identity Mapping (입력 그대로 전달)
스킵된 레이어는 아무 계산도 하지 않고, 입력을 그대로 다음 레이어로 넘김
Transformer에서 output = input + f(input) 에서 f(input) = 0
기존 방법들은 이걸 썼음. (SkipDecode, Unified Layer Skipping)
Scaling (입력에 보정 계수 곱하기) - AdaSkip
단순히 입력 aj를 출력 대신 쓰면 크기 차이 때문에 deviation(편차)이 생김
그래서 각 sublayer에 대해 입력과 출력 벡터 크기 비율을 평균 내서 보정 계수(scale factor)를 계산